Transformers, Recurrent Neural Networks (RNNs), and State Space Models (like S4) share the common goal of processing sequential data. Despite their architectural differences, these models aim to capture dependencies across time steps to solve tasks such as language processing, time-series forecasting, and speech recognition.
My goal of this post is to
- look into technical details of transformers, RNNs, and S4 models,
- apply these models to the Electricity Transformer Dataset (ETD) from [Zhou2021],
- and deepen my own understanding of all three models.
I will provide you with a detailled technical walk-through of all three models. Following files are available:
- environment.yml
- walkthrough.ipynb
- s4.py (github.com/state-spaces)
- ETTh1.csv
- ETTh2.csv
- ETTm1.csv
- ETTm2.csv
In addition to this technical walk-through of the models, I provide you with some useful links at the end of the page.
Environment for prototyping
We will make use of the following mamba/conda environment.yml.
I use the command mamba env create -f environment.yml to install the environment and download all necessary packages.
You can install the packages also via pip.
name: sur-blog-transformers-s4
channels:
- defaults
- pytorch
dependencies:
- jupyter
- matplotlib
- numpy
- pandas
- pip
- plotly
- python>=3.11
- pytorch>=2
- seaborn
- torchvision
- tqdm
With mamba activate sur-blog-transformers-s4 you can activate the environment and within the environment jupyter notebook is started by invoking jupyter notebook.
The above packages are then available in the installed python kernel of the running jupyter notebook.
Import the packages in your jupyter notebook:
import math
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import matplotlib.pyplot as plt
Let’s start with the data.
The Electricity Transformer Dataset
From github.com/zhouhaoyi/ETDataset you can download the files we are working with [Zhou2021]. You should have local files ETTh1.csv, ETTh2.csv, ETTm1.csv, ETTm2.csv available. The ETTh1.csv can also be found on kaggle.com if you need an alternative source.
# Load the dataset
df = pd.read_csv('ETTh2.csv')
# Let's focus on just one feature for simplicity: 'OT' (oil temperature)
data = df['OT'].values
data[:10]
array([38.66199875, 37.12400055, 36.46500015, 33.60850143, 31.85050011,
30.53199959, 30.09300041, 29.87299919, 29.65299988, 29.21349907])
Let’s normalize the data:
data_mean = data.mean()
data_std = data.std()
normalized_data = (data - data_mean) / data_std
normalized_data[:10]
Observe how the values in our data are now centered around their mean and lie close around 0 and 1:
array([1.01385425, 0.88447943, 0.82904499, 0.58875925, 0.44087799,
0.32996708, 0.29303892, 0.27453264, 0.25602652, 0.21905617])
We can plot the time series for each step from 0 up to 17320 and obtain the following graph:
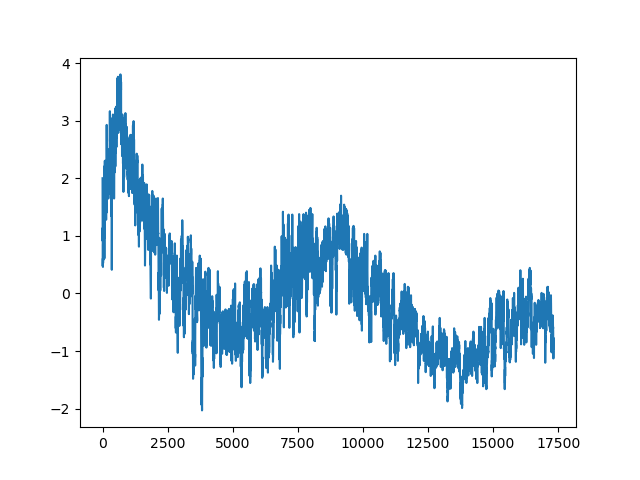
The graph matches nicely with the original plot on github.com/zhouhaoyi/ETDataset. For sequence models such as RNNs, Transformers, and S4 models it is sufficient for now that we know that we are working with a 1d time series, i.e. we have one value per time step.
{kind=link}
We further make a tweak to the dataset as to obtain sequences of same lengths and conduct few-step ahead predictions. For this, we employ the following utility function to transform the dataset into sequences:
# Define a function to create sequences
def create_sequences(data, seq_length):
sequences = []
targets = []
for i in range(len(data) - seq_length):
sequences.append(data[i:i + seq_length])
targets.append(data[i + seq_length])
return np.array(sequences), np.array(targets)
.. and apply it to our normalized data to obtain sequences of length 50 with a running shift:
# Create sequences with a sequence length of 50
SEQ_LENGTH = 50
X, y = create_sequences(normalized_data, SEQ_LENGTH)
A single sample for a model now consists of a tuple of features and the prediction target of which the features have 50 steps and the target is a single value. Inspect the first five values of our first two data points with index #0 and index #1:
X[0][:5], X[1][:5]
(array([2.00156797, 1.68184735, 1.68184735, 1.36224319, 1.00150869]),
array([1.68184735, 1.68184735, 1.36224319, 1.00150869, 0.91132507]))
The shift from the first to the second sequence can be easily observed: sequence 1 starts with 2.00 and continues with 1.68 and sequence 2 starts with this second value 1.68. Each sequence contains 50 values and each consecutive sequence shifts the data by one value. The following visual illustrates the sequences:

The target for prediction when observing a sequence is then the next following value after the sequence ended. So its a one-step forecast after observing 50 values. The sequences can be easily extended to arbitrary lengths as by tweaking the SEQ_LENGTH variable.
We are now walking through the details of the three models, namely the Recurrent Neural Network, the Transformer, and the S4. Each one of them is a possible solution concept to the provided problem of predicting the next value in the time series.
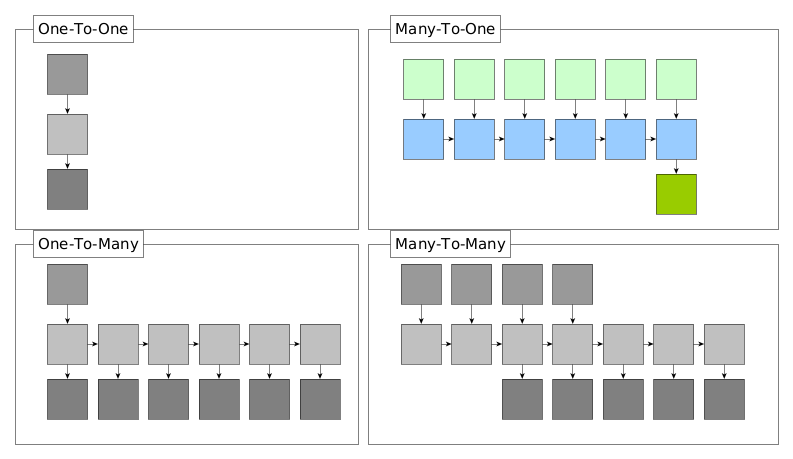
With the ETT data we are tackling a many-to-one sequence prediction problem. As we have a value to predict and not a single class or label, it can also be considered as a multi-variate regression problem where the prediction outcome is a single scalar variable.
Recurrent Neural Network Model
We are working with the following pytorch model.
The complexity of a RNN is hidden in line 6 in self.rnn = nn.RNN and the provided code is just a wrapper to work with it.
class RNNModel(nn.Module):
def __init__(self, input_size=1, hidden_size=64, num_layers=2):
super(RNNModel, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, 1)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
out, _ = self.rnn(x, h0)
out = self.fc(out[:, -1, :])
return out
The torch.nn.RNN module in PyTorch implements a Recurrent Neural Network (RNN), a key architecture for processing sequential data. RNNs handle inputs step-by-step, updating a hidden state with each input, and are widely used in tasks like time-series forecasting and natural language processing.
The documentation in PyTorch can be found here and the implementation is provided in a torch.nn.RNNBase and the torch.nn.RNN class.
The documentation notes the following equation:
$$h_t = tanh(x_tW^T_{ih}+b_{ih}+h_{t-1}W^T_{hh}+b_{hh})$$
where $h_t$ is the hidden state at time $t$, $x_t$ is the input at time $t$, and $h_{(t−1)}$ is the hidden state of the previous layer at time $t-1$ or the initial hidden state at time 0.
The actual code of torch.nn.RNN is more complex but the equation is reflected in the following simplified version of the forward() method of the RNN class:
def forward(self, input, hx=None):
...
for t in range(seq_len):
hidden = self.activation(torch.matmul(input[t], self.weight_ih) + torch.matmul(hidden, self.weight_hh))
if self.bias:
hidden += self.bias_ih + self.bias_hh
...
The upper $T$ in e.g. $W^T_{ih}$ denotes the transposed of the matrix and let us change the direction of the matrix multiplication.
The code for the multiplication $x_tW^T_{ih}$ then simply is torch.matmul(input[t], self.weight_ih).
The parameters of the RNN model can be inspected with model_rnn.rnn._flat_weights_names.
For this, we create a new instance and have a look into the basic parameters.
model_rnn = RNNModel().to('cuda' if torch.cuda.is_available() else 'cpu')
model_rnn.rnn._flat_weights_names
['weight_ih_l0',
'weight_hh_l0',
'bias_ih_l0',
'bias_hh_l0',
'weight_ih_l1',
'weight_hh_l1',
'bias_ih_l1',
'bias_hh_l1']
The weight_ih_l0 now refers to the input-to-hidden parameters $W^T_{ih}$ in the first layer and weight_ih_l1 in the second layer. Hidden-to-hidden parameters $W^T_{hh}$ are contained in weight_hh_l0 and weight_hh_l1. Observe, that we initialized the model with two layers such that we apply the equation twice. Increasing the num_layers=2 parameter of the model also increases the number of these parameter matrices.
So what happens when the input sequence $x$ is passed into the RNN model?
- A hidden layer state $h_0$ of shape [2, 64, 64] is initialized. The input $x$ and $h_0$ are passed into the RNN class to its forward method
- For each element in the sequence (
for t in range(seq_len)), a hidden state is computed based on the above equation. For the first hidden state, the initial $h_0$ is used and multiplied with the hidden-to-hidden weights and added to the input multiplied by the input-to-hidden weights. This happens per each layer of the RNN. - Stacked output: after looping through all time steps, the list output contains the hidden states for all time steps. This is stacked along the sequence dimension using torch.stack(output, dim=0)
- The last hidden state is mapped to an output value and together with the new hidden state, the result is returned.
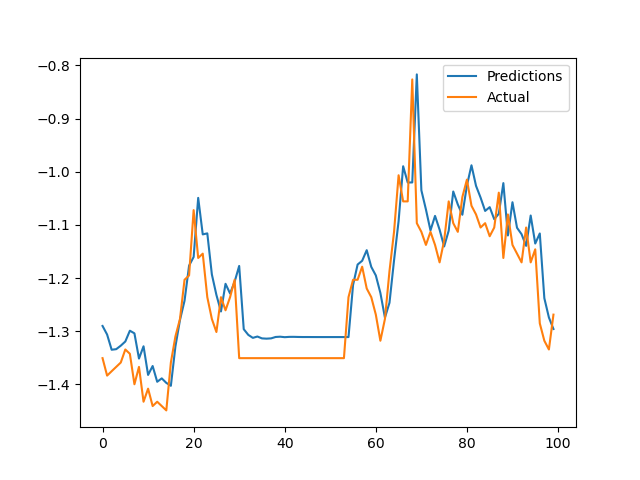
In the walkthrough.ipynb, a training based on the data and subsequent evaluation is conducted. Based on a test set (that was not used for training), the following prediction based on the RNN model was made:
Transformer Model
The Transformer encoder layer is widely used for time-series data. The input is typically shaped as (B,L,D) where:
- B is the batch size,
- L is the sequence length (number of time steps),
- D is the number of features (dimensions).
Since Transformers are originally designed for natural language processing (where token positions are important), positional encodings are added to provide temporal context to the model. These encodings are typically sinusoidal or learned embeddings that are added to the input sequence.
Each Transformer Encoder Layer consists of the following subcomponents: a multi-head self-attention mechanism, a feedforward network, and residual connections and layer normalizations.
The core equation for the self-attention mechanism is: $$\text{attn}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) = \text{softmax}(\frac{\mathbf{Q} {\mathbf{K}}^\top}{\sqrt{d_k}})\mathbf{V}$$ Where $Q$, $K$, and $V$ represent the query, key, and value matrices, and $d_k$ is the dimension of the keys.
In the context of the self-attention mechanism, the input sequence is first transformed into three key matrices:
- Query ($Q$): Represents the current element for which we’re computing attention (what are we focusing on?).
- Key ($K$): Represents all the elements that the query will attend to (who will provide context to the query?).
- Value ($V$): Contains the information from each element that we want to aggregate based on attention (what do we want to extract from the other elements?).
For a given query (representing one time step), we compute a dot product with all the key vectors (including the key for the same time step and other steps in the sequence). This gives a similarity score that indicates how much focus the current time step (query) should give to the other time steps (keys). Mathematically, this can be written as: $$\text{score}(q_i,k_j) = q_i\cdot k_j^T$$ where $q_i$ is the query vector for the $i$-th time step, and $k_j$ is the key vector for the $j$-th time step. Each time step in the input sequence has its own query, key, and value vectors.
To prevent the dot products from becoming too large as the dimensionality increases, the dot product result is scaled by the square root of the dimensionality of the key vectors, $d_k$: $$\text{scaled\_score}(q_i,k_j) = \frac{q_i\cdot k_j^T}{\sqrt{d_k}}$$ This scaling ensures more stable gradients during training.
The softmax function is applied to the scaled scores to convert them into probabilities. The softmax normalizes the scores so that they sum to 1, making them interpretable as attention weights. $$\text{attn\_weight}(q_i,k_j) = \frac{exp\left(\frac{q_i\cdot k_j^T}{\sqrt{d_k}}\right)}{\sum_{j=1}^n exp\left(\frac{q_i\cdot k_j^T}{\sqrt{d_k}}\right)}$$ This step essentially determines how much weight each time step (the key) should contribute to the final output for the current query.
Finally, we compute a weighted sum of the value vectors using the attention weights computed in the previous step. This gives the attended output for the current query: $$\text{output}(q_i) = \sum_{j=1}^n \text{attn\_weight}(q_i,k_j)\cdot v_j$$ Here, $v_j$ is the value vector corresponding to the $j$-th time step, and the result is a context-aware representation of the sequence for the current query.
The softmax operation serves two main purposes:
- Normalization: It converts raw similarity scores (dot products) into normalized probabilities, ensuring that they are in the range [0,1] and sum to 1. This allows the model to make the weights more interpretable and stable.
- Focus on Relevant Parts: By using softmax, the model assigns higher probabilities (weights) to the most relevant parts of the sequence, allowing it to “focus” on these parts more during processing. Less relevant parts get lower weights.
Enough with the theory so far, let’s have a look into the following module of a transformer for time series.
It is based on a positional encoding module and, like in the RNN case, is a wrapper for the actual pytorch implementation, hidden in lines 7 and 8 with self.encoder_layer = nn.TransformerEncoderLayer(..) and self.transformer_encoder = nn.TransformerEncoder(..), respectively.
class TransformerTimeSeries(nn.Module):
def __init__(self, input_size=1, d_model=64, nhead=8, num_layers=2, dim_feedforward=128, dropout=0.1):
super(TransformerTimeSeries, self).__init__()
self.d_model = d_model
self.pos_encoder = PositionalEncoding(d_model, dropout)
self.encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead,
dim_feedforward=dim_feedforward, dropout=dropout)
self.transformer_encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=num_layers)
self.fc = nn.Linear(d_model, 1) # Final linear layer to map the Transformer output to a single value
self.input_projection = nn.Linear(input_size, d_model) # Input projection to match the model dimension
def forward(self, src):
# Project the input to d_model dimensions
src = self.input_projection(src)
# Add positional encodings
src = self.pos_encoder(src)
# Pass through the Transformer Encoder
output = self.transformer_encoder(src)
# We take the output at the last time step and map it to the final prediction
output = self.fc(output[:, -1, :]) # Output at the last time step
return output
Positional encoding is a crucial component in the Transformer architecture that provides information about the positions of tokens in a sequence. Unlike models such as recurrent neural networks (RNNs), which inherently process input sequentially, Transformers process entire sequences in parallel. This parallelism removes the implicit notion of ordering between tokens, which is problematic because order often contains important information (e.g., the word order in a sentence or time order in a time series).
To compensate for the lack of sequence information in Transformers, positional encodings are added to the input embeddings, allowing the model to distinguish between different positions in the input sequence. Positional encoding can be either fixed (predefined functions) or learned during training as part of the model’s parameters. The positional encoding has the same dimension as the input embeddings. This allows the positional encoding to be added directly to the token embeddings. In the most common implementation, the positional encoding is derived from sinusoidal functions, which allow the model to generalize to sequence lengths it hasn’t seen during training.
In the original Transformer paper (“Attention is All You Need”) [Vaswani2017], a sinusoidal positional encoding is used, which provides fixed encodings based on sine and cosine functions of different frequencies. We make use of the same idea here.
class PositionalEncoding(nn.Module):
"""Inject some information about the relative or absolute position of the tokens in the sequence."""
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
Given a position $pos$ and a dimension $i$ in the embedding, the positional encoding is defined as: $$\text{pos}_{(pos,2i)} = sin\left(\frac{pos}{10000\frac{2i}{d_{model}}}\right)$$
$$\text{pos}_{(pos,2i+1)} = cos\left(\frac{pos}{10000\frac{2i}{d_{model}}}\right)$$
Where $pos$ is the position in the sequence $(0, 1, 2, \dots, n-1)$, $i$ is the dimension index in the embedding vector, and $d_{model}$ is the dimensionality of the embedding space. This results in different sine and cosine values for each position and each dimension of the embedding. The values are cyclical, allowing the model to capture both absolute and relative positions. The sine function is used for even indices of the embedding vector, and the cosine function is used for odd indices.
An exemplary simplified version of the torch.nn.TransformerEncoderLayer looks like the following:
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1):
super(TransformerEncoderLayer, self).__init__()
# Multi-head self-attention
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Feed-forward layers
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
# Layer normalization
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
# Dropout layer
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
# Activation function
self.activation = nn.ReLU()
def forward(self, src, src_mask=None, src_key_padding_mask=None):
# Self-attention block
src2 = self.self_attn(src, src, src, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src = self.norm1(src)
# Feed-forward block
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
When a sequence is fed into the transformer model, the following technical steps are undertaken:
- The input is projected from input_size=1 to the internal model dimension d_model=64 (don’t get confused that we have the same batch size of 64). You can learn about the detailled shapes of the matrix multiplications by changing the internal dimension or the batch size to different sizes in the walkthrough.ipynb.
- The positional encoding is applied to the input. The encoding was pre-computed and is kept unchanged for the maximum length of i.e. 5000 steps. Take a look into the part “Inspection of the Transformer components” in the walkthrough.ipynb.
- The positional encoded input is fed into the
torch.nn.TransformerEncoderLayer. - Masks as in line 770 on github.com and the self-attention mechanism as exemplified with
self.self_attn(src, src, src, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)are applied (compare the reducedTransformerEncoderLayercode). We will take another look into this in short. - Dropout and layer normalization is applied. However, the simplified code is not optimal, as according to Xiong et al. [Xiong2020] pre-layer-normalization in Transformers seems to be beneficial for learning with gradients – one of many details making the pytorch implementation quite complex.
The final predictions of the transformer model applied on the ET dataset looks as:
![]()
Applying the Attention Head
..
Structured State Space (S4) Model
For our walkthrough, we orientate on the implementation at github.com/state-spaces/s4 and make use of the s4.py for a S4Block class.
The State Space Models, particularly the Structured State Space (S4) model, are designed to handle sequential data using efficient convolution techniques. The S4 model represents sequences using state-space equations, where the dynamics of the system are described by linear time-invariant (LTI) models. S4 leverages the Fast Fourier Transform (FFT) for fast convolution. It replaces the recurrent nature of traditional models like RNNs with more efficient convolutional operations. The model uses a recursive approach to propagate the states of the system across time steps and thus carries parallels to recurrent neural nets (RNNs).
class S4Model(nn.Module):
def __init__(self, input_size=1, d_model=64, num_layers=2):
super(S4Model, self).__init__()
self.d_model = d_model
self.encoder = nn.Linear(input_size, d_model)
self.norm = nn.LayerNorm(d_model)
self.s4 = S4Block(d_model) # The S4 block from the library
self.decoder = nn.Linear(d_model, 1) # Final linear layer for regression output
def forward(self, x):
# Input x is shape (B, L, d_input)
h = self.encoder(x) # (B, L, d_input) -> (B, L, d_model)
# Pre-Norm
h = h.transpose(-1, -2) # (B, L, d_model) -> (B, d_model, L)
h = self.norm(h.transpose(-1, -2)).transpose(-1, -2)
# Pass through S4
h, _ = self.s4(h)
h = h.transpose(-1, -2) # (B, L, d_model) -> (B, d_model, L)
# Pooling: average pooling over the sequence length
h = h.mean(dim=1) # (B, d_model, L) -> (B, d_model)
# Output at the last time step
h = self.decoder(h) # (B, d_model) -> (B, d_output)
return h
The input to the S4 model is a sequence, typically in the form of a matrix $x$ with dimensions $(\text{batch\_size}, \text{seq\_len}, \text{d\_model})$, where:
- $\text{batch\_size}$: Number of sequences in a batch.
- $\text{seq\_len}$: Length of each sequence.
- $\text{d\_model}$: Dimensionality of the input features.
The first step is to project the input $x$ into a higher-dimensional space using a linear transformation. This projects the input from $d=1$ into a state space representation with $d\_state=64$ dimensions. Note, that we have a sequence length $L = 50$ and a single value per time step, such that $d=1$. After this projection, the input is reshaped into dimensions $(\text{batch\_size}, \text{seq\_len}, \text{channels}, \text{d\_state})$ and is permuted for the convolution operation. This takes place in the attached s4.py (#L1892) or on github in the S4Block.forward().
Instead of updating the states recurrently, the S4 model leverages FFT-based convolution. This can be found in the FFTConv class in line #L1633 or, again, on github in the respective line. The state-space model defines the dynamics of the system through a kernel representing the recurrent updates. This kernel is precomputed:
# From #L1710
l_kernel = L if self.L is None else min(L, round(self.L / rate))
k, k_state = self.kernel(L=l_kernel, rate=rate, state=state) # (C H L) (B C H L)
The model computes the convolution between the input sequence and the kernel in the frequency domain.
Different kernels are pre-defined:
kernel_registry = {
's4d': SSMKernelDiag,
'diag': SSMKernelDiag,
's4': SSMKernelDPLR,
'nplr': SSMKernelDPLR,
'dplr': SSMKernelDPLR,
}
The input is transformed into the frequency domain using FFT. The kernel (which is a representation of the system’s state dynamics) is also transformed using FFT. The convolution operation, which would normally be computationally expensive in the time domain, is reduced to element-wise multiplication in the frequency domain. After the multiplication, Inverse FFT is applied to transform the result back to the time domain, yielding the output $y$. In traditional RNNs, the recurrent state update is expensive and scales linearly with sequence length. FFT-based convolution, on the other hand, reduces the computational complexity by transforming convolution into efficient point-wise multiplication.
Although S4 is not a recurrent neural network, it mimics the behavior of recurrent models by using the kernel (which implicitly encodes the state updates). Each element of the sequence interacts with past elements in a recurrent-like manner through the kernel, allowing the model to capture long-range dependencies. The kernel in S4 represents a state-space model, which effectively summarizes how the current state evolves based on the input sequence. This convolutional operation captures the recurrence implicitly, allowing the model to handle long sequences more efficiently than traditional RNNs.
After the S4Block was applied, we are left with a shape $(\text{batch\_size}, \text{d\_model}, \text{seq\_len})$ and aggregate it e.g. by a sum or a mean: h = h.mean(dim=1).
An output projection casts the state space dimensionality to the required output dimension (which is again $d=1$):
h = self.decoder(h).
Summary
The notebook walkthrough.py provides a technical playground to get familiar with recurrent neural networks, transformers, and state space models on a 1-d data set over reasonable time steps ($L=50$). Technically, the models can be scaled to more complex problems such as language modeling but show the basic underlying workings.
Recurrent neural networks can suffer from long ranges and vanishing or exploding gradients. They are very dependent on the activation function used. Transformers take sequences as whole inputs into account and need positional encodings to remember the ordering of the sequence. They have proven very powerful but are complex with respect to the input sequence length. State space models with recent tweaks provide an interesting new approach by acting like recurrent models, but leveraging the power of convolutions and kernels to quickly calculate the dependencies across time.
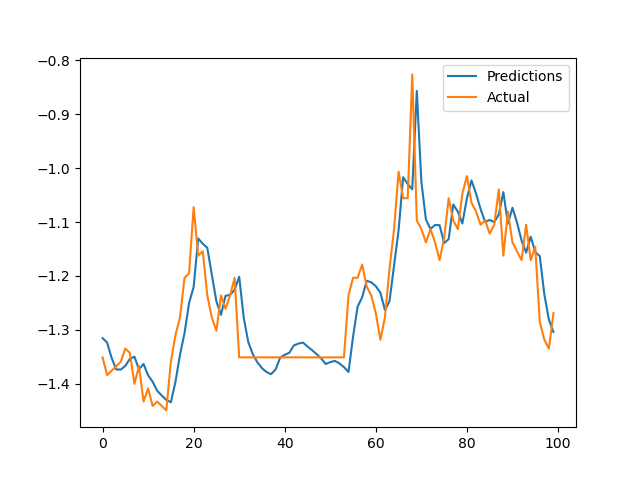
The full evaluation on the Electrictiy Transformer data set can be seen in the following plot:
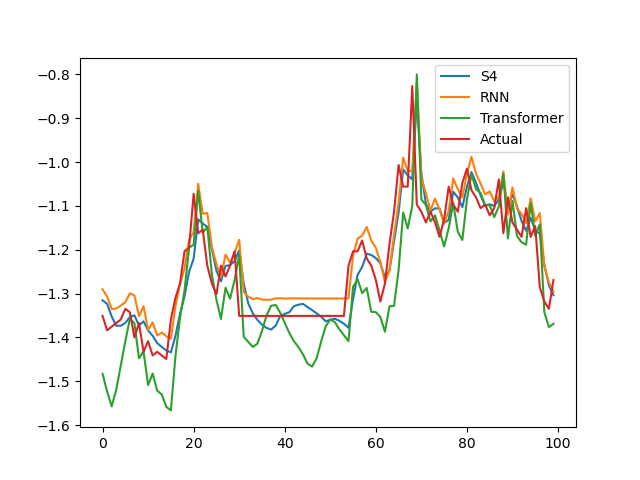
Links
- maartengrootendorst.com - A Visual Guide to Mamba and State Space Models
- harvard.edu:
- lilianweng.github.io: The transformer family (v2)
- AI Coffee Break with Letitia: Mamba and State Space Models explained
- Yannic Kilcher: Mamba Selective State Spaces
- AI Coffee Break with Letitia: Positional embeddings in transformers EXPLAINED | Demystifying positional encodings
References
@phdthesis{stier2024struct,
title={Structure of Artificial Neural Networks - Empirical Investigations},
author={Julian Stier},
school={University of Passau},
year={2024},
month={April},
type={PhD thesis}
}
@inproceedings{zhou2021informer,
title={Informer: Beyond efficient transformer for long sequence time-series forecasting},
author={Zhou, Haoyi and Zhang, Shanghang and Peng, Jieqi and Zhang, Shuai and Li, Jianxin and Xiong, Hui and Zhang, Wancai},
booktitle={Proceedings of the AAAI conference on artificial intelligence},
volume={35},
number={12},
pages={11106--11115},
year={2021}
}
@article{li2018learning,
title={Learning deep generative models of graphs},
author={Li, Yujia and Vinyals, Oriol and Dyer, Chris and Pascanu, Razvan and Battaglia, Peter},
journal={arXiv preprint arXiv:1803.03324},
year={2018}
}
@article{vaswani2017attention,
title={Attention is all you need},
author={Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin},
journal={Advances in Neural Information Processing Systems},
year={2017}
}
@inproceedings{xiong2020layer,
title={On layer normalization in the transformer architecture},
author={Xiong, Ruibin and Yang, Yunchang and He, Di and Zheng, Kai and Zheng, Shuxin and Xing, Chen and Zhang, Huishuai and Lan, Yanyan and Wang, Liwei and Liu, Tieyan},
booktitle={International Conference on Machine Learning},
pages={10524--10533},
year={2020},
organization={PMLR}
}